[ orcid=0000-0002-3228-6790, email=ymalaise@vub.be, url=https://wise.vub.ac.be/member/yoshi-malaise, ]
[ orcid=0000-0003-0314-7107, email=mvdewync@vub.be, url=https://maximvdw.be/profile/card, ]
[ orcid=0000-0001-9916-0837, email=bsigner@vub.be, url=https://beatsigner.com, ]
Personal Data Vault , Intelligent Tutoring Systems , Exercise Recommendation
1 Introduction
The use of Intelligent Tutoring Systems (ITS) to adapt the recommendation of exercises based on individual learners has proven to be effective [1]. Evidence suggests that more personalised learning leads to increased learner agency, self-reliance and motivation [2]. However, the move towards smart learning systems is not without costs. Intelligent Tutoring Systems typically require that all of the exercises are stored in one centralised system that is often also monitored by teachers and persons who are responsible for ultimately grading the students. Previous studies revealed that implementing electronic performance monitoring can result in lower job satisfaction, increased stress levels, reduced autonomy, and it can further be perceived as a violation of trust [3]. In ideal circumstances, the learning environments should also offer a safe space for students to practise on problems they find interesting or challenging, without having to worry about how they will be perceived by teachers. To give an example, a student might be worried that the perception of the teacher might change if they are still shown to be struggling with material from previous years.
In the following, we propose a solution to this problem based on the Solid specification where (a) the same user progress can be used across multiple learning applications to provide a smooth flow state and (b) a student can opt in to share progress with individual applications for training the model, but without having to provide teachers access to their entire performance for individual exercises. We discuss the solution by answering some open questions posed by Malaise and Signer [4]. They proposed the Explorotron prototype for programming education. In this prototype, there are multiple smaller sub-applications called study lenses, each taking a source code file and generating exercises based on certain difficulty levels matching the PRIMM methodology [5]. While their tool offers the possibility to suggest learning experiences based on logical progression through built-in study lenses, the authors conclude with a few major challenges to overcome:
Students can generate exercises from any source file, so generated content is never used by other students, leading to a cold start problem that makes recommendations challenging.
Students should be free to decide which data they want to share and with whom they want to share it.
Third-party developers should be able to contribute custom exercise generators (study lenses) transparently—the same recommendations/profiling should work across the board.
2 Solution
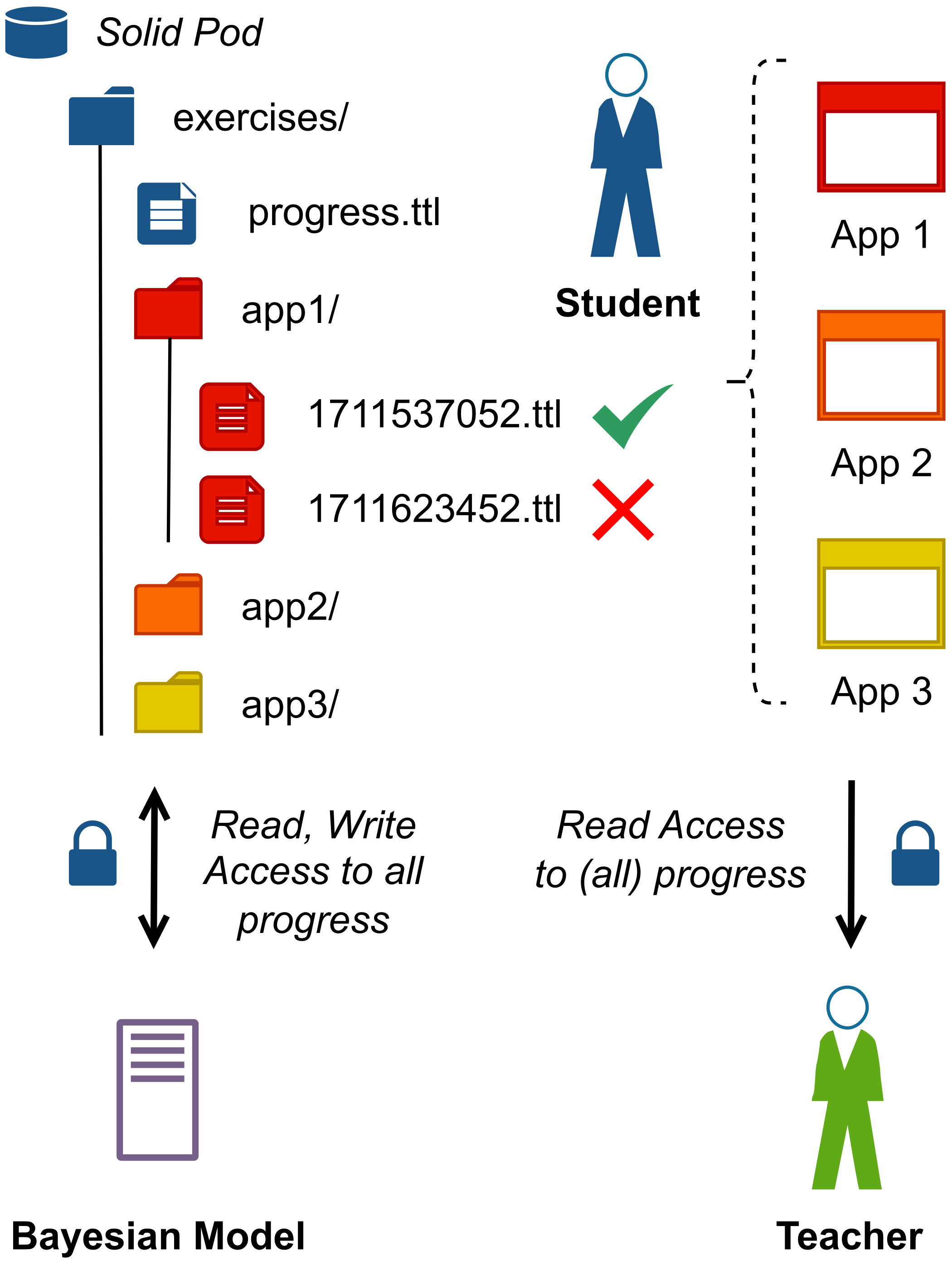
For our demonstration, we assume that student modelling happens through the use of Bayesian Knowledge Tracing (BKT) [6] which is a common approach in the design of Intelligent Tutoring Systems. However, note that with some modifications, other approaches could also be supported. BKT is a probabilistic model that requires four parameters to be fitted for each learning object as illustrated in Figure 1.
P(Lt): The probability that the topic being covered by the learning object is mastered at time t. A value P(L0) has to be provided to indicate the chance the user knows the topic before attempting any exercise. Note that the topics are defined as a combination of the knowledge topic and the difficulty level as defined later in Section 2.1.
P(S): The probability that the user makes a slip, i.e. gets it wrong even though they know the topic.
P(G): The probability that the user makes a lucky guess and gets the answer right even though they do not know the topic.
P(T): The probability that the user actually learns the topic while performing this exercise.

Based on these values, we can then calculate the updated probability that a topic (e.g. “Arrays") is mastered each time the user is presented with a new exercise about this topic (Lt + 1) based on whether they succeeded or failed solving the exercise. It is important to note that all these probabilities are exercise dependent and will as such not be shared across the applications except for P(Lt). This value is the probability that the user knows a topic, which can be shared across any application as long as they are referring to the same topic.
We aim to store the result of every exercise the user performs within a personal data vault, together with the calculated P(Lt) for every topic and difficulty level pair as shown in Figure [fig:overview]. Developers of educational applications could then request limited-time access to the entries of all of their users in order to fit their models, without the need to permanently own all the data. Shared information, such as the P(Lt), will further make it easier for other developers to contribute their own extensions that provide exercise recommendations.
<> a schema:ReplyAction; # A reply to a question
dct:created "2024-03-28T11:57"^^xsd:dateTime;
schema:agent <http://.../profile/card#me>;
# Exercise question
schema:parentItem [ a schema:Question;
schema:name "What is the output of ...?"@en;
schema:educationalLevel primm:Predict;
schema:eduQuestionType "Flashcard"@en;
foaf:topic dbr:Array;
foaf:agent <https://app1.org/>. # Creator
];
schema:result [ a schema:Answer; # User answer
schema:answerExplanation [ ... ];
schema:review [ a schema:Review;
# The grade of the answer (e.g. 5 out of 5)
schema:reviewRating 5; schema:bestRating 5.
]
].[]Example reply on a question generated by app #1
using prefixes dbr [7],
schema [8], foaf [9] and
dct [10]
storing exercise results in a Solid Pod
Users can already indicate their topics of interest in their Solid
Pod using the topics of interest predicate from the foaf
vocabulary [9], which can aid educational
recommendation systems to provide exercises that interest the user.
Together with data about the past performance, we can create
personalised learning paths for users based on their strengths and
weaknesses from multiple sources without creating any vendor lock-in and
without claiming ownership of the students’ data.
In addition, the progress of these exercises and topics can optionally be shared with an educator or mentor as illustrated in Figure [fig:overview], allowing for personalised feedback and guidance to further support a user’s learning journey. The fine-grained control over the data also allows students to share the information on topics they are currently covering in class, while preventing the need to share that they are still working on other topics that they do not want to share.
2.1 Exercises and Progress
Each topic has a set of exercises with their individual difficulty
level. With our proposed solution we use the existing PRIMM
principles [5] to identify the five stages
of difficulties for exercises. These stages include the ability to
predict the output of a piece of code, run a piece of
code, investigate a piece of code and answer some questions
about its structure, modify a piece of code so the behaviour
changes to a new desired result and finally, make a similar
piece of code from scratch. Together, these five principles identify the
logical progression of difficulty levels with which to look at a piece
of code from the perspective of a student. Listing 2 illustrates an example exercise and
the answer given to this exercise that includes the difficulty level1 using the
educationalLevel predicate.
A further extension of the architecture would allow third-party developers to share the capabilities of their plugins with regards to what type of content their plugins could provide so the recommendation engine can be a fully separate component querying all content providers included by the user without it being centrally controlled by one individual.
<#progress_arrays_predict> a sosa:ObservableProperty ;
rdfs:label "Prediction progress"@en ; ssn:isPropertyOf <#me> ;
foaf:topic dbr:Array ; schema:educationalLevel primm:Predict .
<#1711623452> a sosa:Observation ; # P(L_(t+1))
sosa:usedProcedure dbr:Bayesian_Knowledge_Tracing ;
dct:created "2024-03-28T11:57"^^xsd:dateTime ;
foaf:agent <https://app1.org/> ; sosa:observedProperty <#progress_array> ;
sosa:hasResult [ qudt:floatPercentage "38.12"^^xsd:float ] .
<#1711537052> a sosa:Observation ; # P(L_t)
sosa:usedProcedure dbr:Bayesian_Knowledge_Tracing ;
dcterms:created "2024-03-27T11:57"^^xsd:dateTime ;
foaf:agent <https://app1.org/> ; sosa:observedProperty <#progress_array> ;
sosa:hasResult [ qudt:floatPercentage "25.0"^^xsd:float ] .Listing [lst:progress] shows multiple observations of user progress for a particular topic at a given time (i.e. P(Lt)). Each observation, described using the SOSA ontology [11], [12], is created by an application. This progress is shared, allowing each educational application to use these observations to determine the current knowledge on a topic.
3 Conclusions
In this paper, we analysed a use case of a digital learning platform that helps students to learn programming but currently has some open challenges on how personalisation and interoperability with third-party developers might be achieved without taking away the learner’s ownership of their data. We then proposed a novel solution to support those tasks by allowing users to store all their exercise results in Solid Pods and giving them full control on how and when applications can access this data. In this work, we assumed that both the users and the application developers could be fully trusted. If more validation and authority is needed, additional layers can be built on top of this system, for example by using a blockchain to verify claims, as described in [13], [14].
The
primm:vocabulary represents a trivial vocabulary to describe the difficulty levels in programming exercises↩︎